Mar 27, 2013
I’ve recently spent some time setting up TLS/SSL encryption (SSSD won’t send a password in clear text when an user will try to authenticate against your LDAP server) on an OpenLDAP istance and as you may know the only way for doing that on a RHEL / CentOS environment is dealing with a Mozilla NSS database (which is, in fact, a SQLite database). I’ve been reading all the man pages of the relevant tools available to manipulate Mozilla NSS databases and I thought I would have shared the whole procedure and commands I used to achieve my goal. Even if you aren’t running an RPM based system you can opt to use a Mozilla NSS database to store your certificates as your preferred setup.
On the LDAP (SLAPD) server
*Re-create .db files
mkdir /etc/openldap/certs
modutil -create -dbdir /etc/openldap/certs
Setup a CA Certificate
certutil -d /etc/openldap/certs -A -n "My CA Certificate" -t TCu,Cu,Tuw -a -i /etc/openldap/cacerts/ca.pem
where ca.pem should be your CA’s certificate file.
Remove the password from the Database
modutil -dbdir /etc/openldap/certs -changepw 'NSS Certificate DB'
Creates the .p12 file and imports it on the Database
openssl pkcs12 -inkey domain.org.key -in domain.org.crt -export -out domain.org.p12 -nodes -name 'LDAP-Certificate'
pk12util -i domain.org.p12 -d /etc/openldap/certs
where **domain.org.key **and **domain.org.crt **are the names of the certificates you previously created at your CA’s website.
List all the certificates on the database and make sure all the informations are correct
certutil -d /etc/openldap/certs -L
Configure /etc/openldap/slapd.conf and make sure the TLSCACertificatePath points to your Mozilla NSS database
TLSCACertificateFile /etc/openldap/cacerts/ca.pem
TLSCACertificatePath /etc/openldap/certs/
TLSCertificateFile LDAP-Certificate
Additional commands
Modify the trust flags if necessary
certutil -d /etc/openldap/certs -M -n "My CA Certificate" -t "TCu,Cu,Tuw"
Delete a certificate from the database
certutil -d /etc/openldap/certs -D -n "My LDAP Certificate"
On the clients (nslcd uses ldap.conf while sssd uses /etc/sssd/sssd.conf)
On /etc/openldap/ldap.conf
BASE dc=domain,dc=org
URI ldaps://ldap.domain.org
TLS_REQCERT demand
TLS_CACERT /etc/openldap/cacerts/ca.pem
On /etc/sssd/sssd.conf
ldap_tls_cacert = /etc/openldap/cacerts/ca.pem
ldap_tls_reqcert = demand
ldap_uri = ldaps://ldap.domain.org
How to test the whole setup
ldapsearch -x -b 'dc=domain,dc=org' -D "cn=Manager,dc=domain,dc=org" '(objectclass=*)' -H ldaps://ldap.domain.org -W -v
Troubleshooting
If anything goes wrong you can run SLAPD with the following args for its debug mode:
/usr/sbin/slapd -d 256 -f /etc/openldap/slapd.conf -h "ldaps:/// ldap:///"
**Possible errors: **
If you happen to see an error similar to this one: “TLS error -8049:Unrecognized Object Identifier.“, try running ldapsearch with its debug mode this way:
ldapsearch -d 1 -x -ZZ -H ldap://ldap.domain.org
Make also sure that the FQDN you are trying to connect to is listed on the trusted FQDN’s list of your domain.org.crt.
Update: as SSSD’s developer Stephen Gallagher correctly pointed out on the comments using ldap_tls_reqcert = allow isn’t a best practice since it may take in Man in the Midle Attacks, adjusting the how to to match his suggestions.
Mar 7, 2013
It’s been more than a month now since I started looking into the many outstanding items we had waiting on our To Do list here at the GNOME Infrastructure. A lot has been done and a lot has yet to come during the next months, but I would like to share with you some of the things I managed to look at during these weeks.
As you may understand many Sysadmin’s tasks are not perceived at all by users especially the ones related to the so-called “Puppet-ization” which refers to the process of creating / modifying / improving our internal Puppet repository. A lot of work has been done on that side and several new modules have been added, specifically Cobbler, Amavisd, SpamAssassin, ClamAV, Bind, Nagios / Check_MK (enabling Apache eventhandlers for automatic restart of faulty httpd processes), Apache.
Another top priority item was migrating some of our services off to the old physical machines to virtual machines I did setup earlier. The machines that are now recycled are the following: (Two more are missing on the list, specifically window (which still hosts art.gnome.org, people.gnome.org and projects.gnome.org due to be migrated to another host in the next weeks) and label. (which still hosts our Jabberd, an interesting discussion on its future is currently ongoing on Foundation-list)
- menubar, our old Postfix host served the GNOME Foundation since 2004 and processed millions of e-mails from and to @gnome.org addresses.
- container, our old main NFS node was serving the GNOME Foundation since 2003, it hosted our mail archives, our FTP archives and all the /home/users/* directories.
- button hosted many services (MySQL databases, LDAP, Mango) and served the Foundation since 2004, a faulty hardware took it down on January 2012.
And if you ever wanted to see how menubar, container and button look like, I have two photos for you with the machines being pulled out the GNOME rack:


Some of the things you may have perceived directly on your skin should be the following:
- Our live.gnome.org istance has been upgraded to the latest MoinMoin stable release, 1.9.6.
- The Services bot has been added to the GIMPNET network and currently manages all GNOME channels, it currently acts as a Nickserv, Chanserv. More information about how you can register your nickname and gain the needed ACLs at the following wiki page.
- Several GNOME services and domains are now covered by SSL as you may have noticed on planet.gnome.org, news.gnome.org, blogs.gnome.org, l10n.gnome.org, git.gnome.org, help.gnome.org, developer.gnome.org.
- Re-design of our Mailman archives as you can see at https://mail.gnome.org/archives/foundation-list. A big “thank you” goes to Olav Vitters for taking the time to rebuild our “archive” script from Perl to Python. About the Mailman topic, someone proposed me the use of HyperKitty, that’s something we will evaluate in the next coming months but I find it a very interesting alternative to the current mail archiving.
What should you expect next?
- Bugzilla will be moved to another virtual machine and will be upgraded to the latest release.
- An Owncloud istance will be setup for all the GNOME Foundation members and GNOME Teams that will need access to it.
- A discussion will be started for setting up a Gitorious istance on the GNOME Infrastructure.
- A long-term item will be rewriting Mango in Django and adding several other features to it than the ones it has now. (ideally voting for Board elections, logins for managing your LDAP information such as your @gnome.org’s alias forward, shutdown of old an unused accounts after a certain period of time, automatic @gnome.org’s alias creation after the “Foundation Membership” flag is selected on LDAP, etc.)
Thanks a lot for all the mails I’ve received during these weeks containing reports and suggestions about how we should improve our Infrastructure! Please stay tuned, a lot more news are yet to come!
Dec 21, 2012
I’ve been looking around for a possible way to connect to the IPv6 internet for some time now and given the fact my provider didn’t allow me to run IPv6 natively I had to find an alternative solution. Hurricane Electrics (HE) provides (for free) five configurable IPv4-to-IPv6 tunnels together with a free DNS service and an interesting certification program.

Willing to test the latest revision of the Internet Protocol on your Debian, Ubuntu, Fedora machines? Here’s how:
1. Register yourself at Hurricane Electrics by visiting tunnelbroker.net.
2. Create a new tunnel and make sure to use your public IP address as your IPv4 Endpoint.
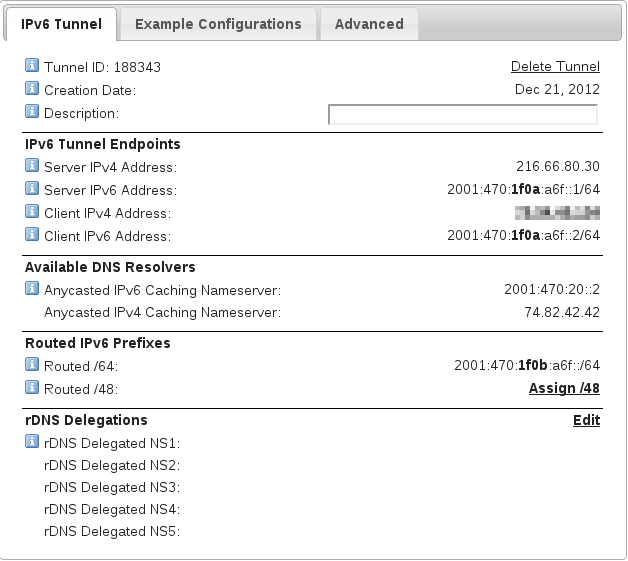
3. Write down the relevant details of your tunnel, specifically:
- Server IPv6 Address: 2001:470:1f0a:a6f::1 /64
- Server IPv4 Address: 216.66.84.46 (this actually depends on which server did you choose on the previous step)
- Client IPv6 Address: 2001:470:1f0a:a6f::2/64
4. Create a little script that will update your IPv4 tunnel endpoint every time your internet IP changes. (this step is not needed if you have an internet connection with a static IP):
#!/bin/bash
USERNAME=yourHEUsername
PASSWORD=yourHEPassword
TUNNELID=yourHETunnelID
GET "https://$USERNAME:$PASSWORD@ipv4.tunnelbroker.net/ipv4_end.php?tid=$TUNNELID"
5. Create the networking configuration files on your computer:
Debian / Ubuntu, on the /etc/network/interfaces file:
auto he-ipv6
iface he-ipv6 inet6 v4tunnel
address 2001:470:<b>1f0a</b>:a6f::2
netmask 64
endpoint 216.66.80.30
local 192.168.X.X (Your PC's LAN IP address)
ttl 255
gateway 2001:470:<b>1f0a</b>:a6f::1
pre-up /home/user/bin/update_tunnel.sh
Fedora, on the ** /etc/sysconfig/network-scripts/ifcfg-he-ipv6** file:
DEVICE=he-ipv6
TYPE=sit
BOOTPROTO=none
ONBOOT=yes
IPV6INIT=yes
IPV6TUNNELIPV4="216.66.80.30"
IPV6TUNNELIPV4LOCAL="192.168.X.X" (Your PC's LAN IP address)
IPV6ADDR="2001:470:<b>1f0a</b>:a6f::2/64"
and on the /etc/sysconfig/network file, add:
NETWORKING_IPV6=yes
IPV6_DEFAULTGW="2001:470:<b>1f0a</b>:a6f::1"
IPV6_DEFAULTDEV="he-ipv6"
You can then set up a little /sbin/ifup-pre-local script to update the IPv4 tunnel endpoint when your dynamic IP changes or simply add the script on the /etc/cron.daily directory and have it executed when you turn up your computer.
6. Change the DNS servers on /etc/resolv.conf:
OpenDNS:
nameserver 2620:0:ccc::2
nameserver 2620:0:ccd::2
Google DNS:
nameserver 2001:4860:4860::8888
nameserver 2001:4860:4860::8844
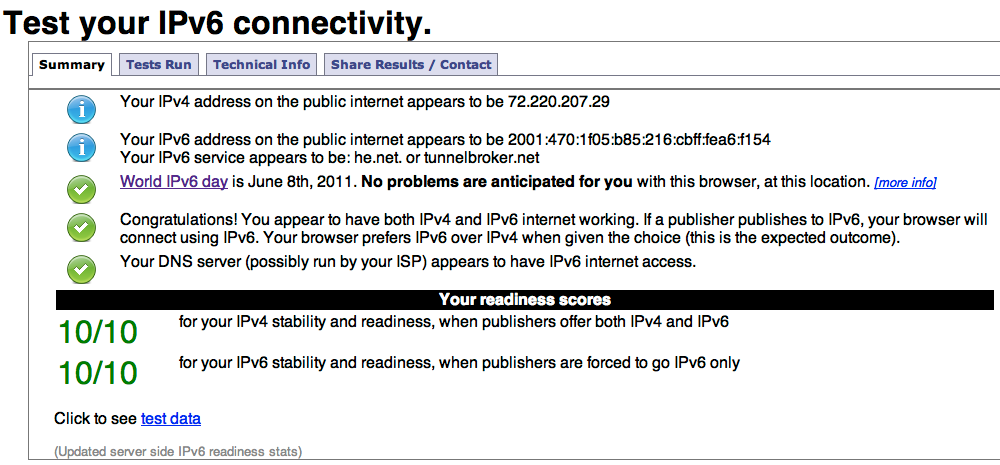
7. Restart your network and enjoy IPv6!
8. If you want to know more about IPv6 take some time for the HE Certification program, you will learn a lot and eventually win a sponsored t-shirt, I just finished mine :-)
EDIT: Be aware of the fact that as soon as the tunnel is up, your computer will be exposed to to the internet without any kind of firewall (the tunnel sets up a direct connection to the internet, even bypassing your router’s firewall), you can secure your machine by using ip6tables. Thanks Michael Zanetti for pointing this out!
Dec 13, 2012
Have you ever heard someone talking extensively about Cloud Computing or generally Clouds? and have you ever noticed the fact many people (even the ones who present themselves as experts) don’t really understand what a Cloud is at all? That happened to me multiple times and one of the most common misunderstandings is many see the Cloud as something being on the internet. Many companies add a little logo representing a cloud on their frontpage and without a single change on their infrastructure (but surely with a price increment) they start calling their products as being on the Cloud. Given the lack of knowledge about this specific topic people tend to buy the product presented as being on the Cloud without understanding what they really bought.

But what Cloud Computing really means? it took several years and more than fifteen drafts to the National Institute of Standards and Technology‘s (NIST) to find a definition. The final accepted proposal:
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
The above definition requires a few more clarifications specifically when it comes to understand where should we focus on while checking for a Cloud Computing solution. A few key points:
- On-demand self-service: every consumer will be able to unilaterally provision multiple computing capabilities like server time, storage, bandwidth, dedicated RAM or CPU without requiring any sort of human interaction from their respective Cloud providers.
- Rapid elasticity and scalability: all the computing capabilities outlined above can be elastically provisioned and released depending on how much demand my company will have in a specific period of time. Suppose the X company is launching a new product today and it expects a very large number of customers. The X company will add more resources to their Cloud for the very first days (where they suppose the load to be very high) and then it’ll scale the resources back as they were before. Elasticity and scalability permit the X company to improve and enhance their infrastructure when they need it with an huge saving in monetary terms.
- Broad network access: capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, tablets, laptops, and workstations).
- Measured service: Cloud systems allow maximum transparency between the provider and the consumer, the usage of all the resources is monitored, controlled, and reported. The consumer knows how much will spend, when and in how long.
- Resource pooling: each provider’s computing resources are pooled to serve multiple consumers at the same time. The consumer has no control or knownledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter).
- Resources price: when buying a Cloud service make sure the cost for two units of RAM, storage, CPU, bandwidth, server time is exactly the double of the price of one unit of the same capability. An example, if a provider offers you one hour of bandwitdh for 1 Euro, the price of two hours will have to be 2 Euros.
Another common error I usually hear is people feeling Cloud Computing just as a place to put their files online as a backup or for sharing them with co-workers and friends. That is just one of the available Cloud “features“, specifically the “Cloud Storage“, where typical examples are companies like Dropbox, Spideroak, Google Drive, iCloud and so on. But let’s make a little note about the other three “features”:
-
Infrastructure as a Service (IaaS): the capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. In this specific case the consumer has still no control or management over the underlying Cloud infrastructure but has control over operating systems, storage, and deployed applications. A customer will be able to add and destroy virtual machines (VMs), install an operating system on them based on custom kickstart files and eventually manage selected networking components like firewalls, hosted domains, accounts.
-
Platform as a Service (PaaS). the capability provided to the consumer is to deploy onto the cloud infrastructure consumer-created or acquired applications created using programming languages, libraries, services, and tools (like Mysql + PHP + PhpMyAdmin or Ruby on Rails) supported by the provider. In this specific case the consumer has still no control or management over the Cloud infrastructure itself (servers, OSs, storage, bandiwitdh etc.) but has control over the deployed applications and configuration settings for the application-hosting environment.
-
Software as a Service (SaaS): the capability provided to the consumer is to use the provider’s applications running on a Cloud infrastructure. The applications are accessible through various client devices, such as a browser, a mobile phone or a program interface. The consumer doesn’t not manage nor control the Cloud infrastructure (servers, OSs, storage, bandwidth, etc.) that allows the applications to run. Even the provided applications aren’t customizable by the consumer, which should rely on limited configuration settings.

The Cloud Computing technology is reasonably the future but can we trust Cloud providers? Are we sure that no one will ever have access to our files except us? and what about governments interested in acquiring a specific customer data hosted on the Cloud?
I always suggest to read deeply both the Privacy Policy and Terms of Use of a certain service before signing in especially when it comes to choose a Cloud storage provider. Many providers have the same aspect, they seem to provide the same resources, the same amount of storage for the same price but legally they may present different problems, and that is the case of Spideroak vs Dropbox. Quoting from the Dropbox’s Privacy Policy:
Compliance with Laws and Law Enforcement Requests; Protection of DropBox’s Rights. We may disclose to parties outside Dropbox files stored in your Dropbox and information about you that we collect when we have a good faith belief that disclosure is reasonably necessary to (a) comply with a law, regulation or compulsory legal request; (b) protect the safety of any person from death or serious bodily injury; (c) prevent fraud or abuse of DropBox or its users; or (d) to protect Dropbox’s property rights. If we provide your Dropbox files to a law enforcement agency as set forth above, we will remove Dropbox’s encryption from the files before providing them to law enforcement. However, Dropbox will not be able to decrypt any files that you encrypted prior to storing them on Dropbox.
It’s evident that Dropbox employees can access your data or be forced by legal process to turn over your data unencrypted. On the other side, Spideroak on its latest update to its Privacy Policy states that data stored on their Cloud is encrypted and inaccessible without user’s key, which is stored locally on user’s computers.
And what about the latest research paper, titled “Cloud Computing in Higher Education and Research Institutions and the USA Patriot Act” written by the legal experts of the University of Amsterdam’s Institute for Information Law stating the anti-terror Patriot Act could be theoretically used by U.S. law enforcement to bypass strict European privacy laws to acquire citizen data within the European Union without their consensus?
The only requirement for the data acquisition is the provider being an U.S company or an European company conducting systematic business in the U.S. For example an Italian company storing their documents (protected by the European privacy laws and under the general Italian jurisdiction) on a provider based in Europe but conducting systematic business in the United States, could be forced by U.S. law enforcement to transfer data to the U.S. territory for inspection by law enforcement agencies.
Does someone really care about the privacy of companies, consumers and users at all? or better does privacy exists at all for the millions of the people that connect to the internet every day?
Nov 22, 2012
I live in a little village close to the city and one of the houses close to my property is for rent since more than ten years. A lot of families and people succeeded in that house and every time someone new joined my Linux evangelist hat jumped in my head.
I’ve always presented myself as a Linux geek to my neighbours and it has been nice seeing how the Linux word evolved (with funny and surprising quotes) during the past ten years in their minds. A friend of mine (Aretha Battistutta) made a little comic strip out of the topic and the result is simply amazing.

Enjoy!
